


人工智能(AI)如今无处不在。这项革命性科技正逐渐渗透到更多领域,影响范围之广将远超出你的想象。不管从事什么业务,每家公司似乎都或多或少与AI产生联系。尤其是如今人们想方设法将AI运用到自动驾驶汽车、物联网(IoT)、网络安全、医疗等诸多领域。企业领导者应当深刻了解如何将AI运用到他们的产品之中,如果率先采用AI获得成功,迟迟未行动的后来者将会陷入困境。
买芯片网专注整合全球优质莱迪思代理商现货资源,是国内领先的Altera(英特尔)、Lattice(莱迪思)、Xilinx(赛灵思 AMD)芯片采购服务平台,买芯片网轻松满足您的芯片采购需求.
然而AI应用种类各异,各有千秋。不同的应用领域要求的AI技术也不尽相同。目前最受关注的应用类别当属嵌入式视觉。这一领域的AI使用所谓的卷积神经网络(CNN),试图模拟人眼的运作方式。在这 篇AI白皮书中,我们主要关注视觉应用,当然其中许多概念也适用于其他应用。
目录
第一节| 网络边缘AI的要求3
第二节| 推理引擎的选择5
第三节| 在莱迪思FPGA中构建推理引擎7
第四节| 在莱迪思FPGA上构建推理模型8
第五节| 两个检测实例10
第六节| 小 结13
网络边缘AI的要求
AI涉及创造一个工作流程的训练模型。然后该模型在某个应用中对现实世界的情况进行推理。因此,AI应用有两个主要的生命阶段:训练和推理。
训练是在开发过程中完成的,通常在云端进行。推理作为一项持续进行的活动,则是通过部署的设备完 成。因为推理涉及的计算问题会非常复杂,目前大部分都是在云端进行。但是做决策的时间通常都十分有限。向云端传输数据然后等待云端做出决策非常耗时。等到做出决策,可能为时已晚。而在本地做决策则能节省那宝贵的几秒钟时间。
这种实时控制的需求适用于需要快速做出决策的诸多领域。例如人员侦测:

其他实时在线的应用包括:

在快速决策这种需求的推动下,目前将推理过程从云端转移到“网络边缘”的诉求异常强烈即在设备上收集数据然后根据AI决策采取行动。这将解决云端不可避免的延迟问题。
本地推理还有两个好处。第一个就是隐私安全。数据从云端来回传输,以及储存在云端,容易被入侵和盗取。但如果数据从未到达设备以外的地方,出现问题的几率就小得多。
另一个好处与网络带宽有关。将视频传送到云端进行实时处理会占用大量的带宽。而在本地做决策则能省下这部分带宽用于其他要求较高的任务。
此外:
o 这类设备通常都是使用电池供电或者,如果是电源直接供电,两者都有散热限制,从而给设备的持续使用造成限制。而与云端通信的设备需要管理自身的功耗的散热问题。
o AI模型演化速度极快。在训练始末,模型的大小会有极大差异,并且在进入开发阶段以前,可能无法很好地估算所需计算平台的大小。此外,训练过程发生的细微改变就会对整个模型造成重大影响,增加了变数。所有这些使得网络边缘设备硬件大小的估计变得尤为困难。
o 在为特定设备优化模型的过程中,始终伴随着权衡。 这意味着模型在不同的设备中可能以不同的方式运行。
o 最后,网络边缘中的设备通常非常小。这就限制了所有AI推理设备的大小。
由此我们总结出以下关于网络边缘推理的几点重要要求:
用于网络边缘AI推理的引擎必须:
功耗低
非常灵活
拓展性强
尺寸小
莱迪思的sensAI能让你开发出完全具备以上四个特征的推理引擎。它包含了硬件平台、软IP、神经网络编译器、开发模块和开发资源,能够助您迅速开发理想中的设计。
推理引擎的选择
将推理引擎构建到网络边缘设备中涉及两个方面:开发承载模型运行的硬件平台以及开发模型本身。
理论上来说,模型可以在许多不同的架构上运行。但若要在网络边缘,尤其是在实时在线的应用中运行模型,选择就变少了,因为要考虑到之前提到的功耗、灵活性和扩展性等要求。
MCU - 设计AI模型的最常见做法就是使用处理器,可能是GPU或者DSP,也有可能是微控制器。但是网络边缘设备上的处理器可能就连实现简单的模型也无法处理。这样的设备可能只有低端的微控制器
(MCU)。而使用较大的处理器可能会违反设备的功耗和成本要求,因此对于此类设备而言,AI似乎难以实现。
这正是低功耗FPGA发挥作用的地方。与增强处理器来处理算法的方式不同,莱迪思的ECP5或UltraPlus FPGA可以作为MCU的协处理器,处理MCU无法解决的复杂任务之余,将功耗保持在要求范围内。由于这些莱迪思FPGA能够实现DSP,它们可以提供低端MCU不具备的计算能力。
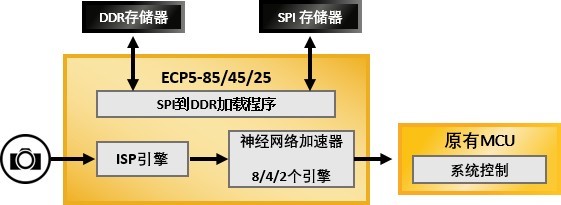
图1:FPGA作为MCU的协处理器
ASICS和ASSP - 对于更为成熟、大批量销售的AI模型而言,采用ASIC或特定应用标准产品(ASSP)或许是可行之道。但是由于工作负载较大,它们在实时在线的应用中的功耗太大。
在此情况下,Lattice FPGA可以充当协处理器,处理包括唤醒关键字的唤醒活动或粗略识别某些视频图像(如识别与人形相似的物体),然后才唤醒ASIC或ASSP,识别更多语音或者确定视频中的目标确实是一个人(或甚至可以识别特定的人)。
FPGA处理实时在线的部分,这部分的功耗至关重要。然而并非所有的FPGA都能胜任这一角色,因为绝大多数FPGA功耗仍然太高,而莱迪思ECP5和UltraPlus FPGA则拥有必要的低功耗特性。
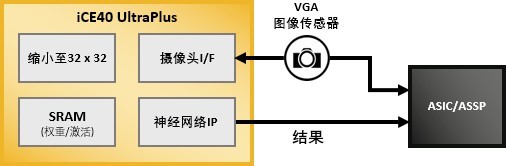
图2 FPGA作为ASIC/ASSP的协处理器
单独运行的FPGA AI引擎 - 最后,低功耗FPGA可以作为单独运行的、完整的AI引擎。FPGA中的DSP在这里起了关键作用。即便网络边缘设备没有其他的计算资源,也可以在不超出功耗、成本或电路板尺寸预算的情况下添加AI功能。此外它们还拥有支持快速演进算法所需的灵活性和可扩展性。

图3 单独使用FPGA的整合解决方案








